As the founder of Linguineo, a voicebot company focused on language learning and open-ended conversations, I believe in the potential of AI to contribute to the greater good. But the explosion of generative AI chatbots raises pertinent questions about how to manage the darker side of simulating human intelligence. In this blog post, I’ll write about one specific approach to control the risk of chatbots and make conversational AI explainable.
An open letter about chatbots
On 31 March, five academics wrote an open letter in response to an allegedly chatbot-caused suicide. A Belgian man in his thirties and a father of two young children, decided to end his life after having a six-week-long conversation about the climate crisis with a generative AI chatbot named ELIZA, making it the first reported chatbot-associated death. More than 200 experts from all walks of life co-signed the letter, showing a growing widespread concern about the potential consequences of a manipulative AI set loose. ELIZA is an older generative AI model.
In our view, the letter is raising valid points. But there are two related things at play that we wish to emphasize: first, that chatbots are human-imitating, and secondly, that generative chatbots can be unpredictable, hallucinating, or biased.
This week, we wrote another #OpenLetter on #AI, urging for action against the risk of manipulation.
— Nathalie Smuha (@NathalieSmuha) March 31, 2023
It was signed by 100 experts & can be read here: https://t.co/JUmL8JwB4a
We hope this leads to broader public debate. It's time for AI providers to take up their responsibility. pic.twitter.com/Zm9G77UtWS
This is where understanding the difference between rule-based and generative chatbots becomes vital. Both are human-imitating but they are not both unpredictable. Rule-based chatbots operate within predefined rules and offer responses based on specific conditions or patterns. This limits undesired outcomes, but also severely limits the capabilities of the chatbot. On the contrary, generative chatbots rely on advanced language models to generate responses using extensive data sets. This fundamental contrast means that generative chatbots are relatively unpredictable, as their answers are not solely guided by pre-established rules.
Our forays into generative AI
Linguineo’s voicebots have always used a lot of machine learning models such as self-trained speech recognition, punctuation, sentence similarity detection and (statistical) intent detection, but never generative AI for response generation. We have been experimenting with generative responses since 2017 though.
Back then, when we received an innovation grant for creating voicebots for language learning, one of our ideas was to explore the generative AI approach. We were inspired by the impressive results achieved by LSTMs (a predecessor of Transformers) in generating Shakespearean texts.
But at that time, we encountered significant challenges in generating coherent and consistent answers. And even if the answers appeared logically, they would show inconsistencies after a few sentences: “My favorite food is sushi.” “Ok good to know! I’ll remember that!” “What is my favorite food?” “Steak with French fries.”
With Transformers, Google BERT and the first LLM’s (Large Language Models; like GPT2, GPT3 and GPT-Neo) that changed. From then on, generative conversations were able to remain relatively consistent for a long period, but at the same time were showing a large degree of bias, were easy to get completely off the rails and were completely uncensored or untruthful. It’s also one of these models that was used with the chatbot-incited suicide.
However, with the advent of ChatGPT and GPT-4, the first models that quite successfully mimic human preference, quite a few of our use cases in education and gaming work well now with generative AI. We have a prototype that uses GPT-4 with a relevance and profanity filter, resupplying the core prompt with every call to avoid that the model starts “following” or “wandering”, and that seems unbreakable (also because the context is always clearly fictional in these cases and we’re not trying to make it a truth answering engine). Although it is probably entirely safe, we still have some doubts about putting it into production.
The risks of generative chatbots
This is because there are still some risks involved.
To be clear, I don’t think generative chatbots shouldn’t be used. Neither am I ruling out that we will ever use truly generative chatbots within our company Linguineo. I just see quite a few risks that still need to be addressed depending on the use case. These risks relate to data privacy, performance, bad task execution, hallucinations, copyright issues, bias, and the fact that in the end you need to put your trust in the model provider. Please expand this paragraph to read more about these risks in detail.
First, there is the risk of the technology being used in a completely wrong way, as was the case with the suicide. You can have certain issues with the newer models too. GPT-4 still makes up a lot of nonsense, such as references to non-existent scientific papers or legal cases, which has caused problems for people already. Using generative AI for cases like this is a lot like an architect creating an unstable bridge, or a web developer putting a website with login live over an unsecure connection: a severe lack of professional knowledge (or deliberate ignorance?) creating a huge liability.
There are also some data privacy and performance risks.
The data privacy risks are probably the least interesting to talk about but they are relevant, at least in the European Union, assuming the model provider is non-European. The underlying problem is that in an open conversation possibly sensitive info – such as a child giving their exact name and location and then talking about their problematic situation at home – is being sent to a processor that is US-based, which is required to share it with the US government in specific circumstances, allowing the US to (according to EU laws illegally) profile the child and their parents. For many parties this risk will be unacceptable.
I was in doubt to include the performance issues. It’s more of a practical problem. A classical chatbot can respond in about 40 milliseconds and has no availability issues, while currently, the ChatGPT and GPT-4 APIs are slow and unstable, with GPT-4 being significantly slower than ChatGPT – on average it takes about 12 seconds for a request – and 1 out of 20 calls ends up in a timeout – “That model is currently overloaded with other requests”. Probably these performance issues will be fixed at some point though and it only means that even companies like Microsoft currently still struggle with deploying these huge models at this scale. The reason why I decided to include it is because these models are clearly a lot heavier than what we’re usually using and have a much bigger environmental impact. One can also wonder that the cheap pricing of these APIs is sustainable.
Then there are the more subtle risks.
There are still many tasks GPT-4 does not do well. To name a few we encountered ourselves: incorrect grammar corrections (correcting something right to wrong) in foreign languages, not rhyming when specifically asked to rhyme in some languages, and not sticking with an instruction to use an extended set of grammar or vocabulary when generating a response. Making wrong assumptions about what it can do can kill a use case.
An even bigger problem for many use cases are the hallucinations. Within our company we have several fictional story-based use cases, such as a fairytale with a lot of background world info, or a murder mystery where it is important to be consistent with many clues and events. The hallucinations posed a problem for all of them. For the fairytale it started adding background info that was clearly inconsistent with the game world, like inventing locations or relations that could not be there. For the murder mystery it started adding clues that made the murder mystery unsolvable. We wanted the chatbot to be consistent with the game world but give good inventive answers at the same time. The 2 only real solutions we found is to create a situation in which it can make up whatever it wants, or to give it a narrow sandbox to operate in. Combining a lot of info about the game world with allowing open answers eventually always lead to large inconsistencies.
There are also possible copyright issues. Some argue generative AI models trained on copyrighted data shouldn’t ever be used for commercial purposes. In my opinion however, I think the copyright issues will boil down to the question “Does this text constitute a clear copyright infringement?”. How the text exactly came to be, will be of less importance. If nothing protected can be found in the resulting text, there is no issue. Otherwise, there is. Sometimes this will be obvious. If the generated text recreates Star Wars or Lord of the Rings scenes for example. Sometimes it will be less clear-cut. For example, if it’s quite literally recreating the works of a lesser known author.

Finally, there are some bias issues. In a conversation about preparing a job interview a female colleague of ours received the suggestion to “make herself look nice for the interview”. These issues we encountered ourselves in a natural setting were never blatant though, at least not in the way the ones with previous models were. The main issue seems to be that these new models mimic some sort of “average” human preference, while in reality, there are as many human preferences as there are humans. Elon Musk questions some side effects of the “woke” ChatGPT, while others might be offended by the remaining traces of gender and ethnic bias. This preference behaves like a ground truth and is not intended to be overridden. I think there will be bigger debates about who controls this preference as adoption increases.
As a developer one can be quite confident these models will stick to this “average human preference” making it relatively safe to use. But one can never be sure. One can ask oneself all the right questions. “Is this an ok use case?” “Can it do the task?” “How will I deal with hallucinations?” “Will it generate any copyright protected responses?” “Can I break it myself during extensive testing?” But in the end, there is always some trust involved towards the model provider.
Therefore, in the EU AI Act that the European Parliament voted for last week, the responsibility of guaranteeing this was moved to the model provider (e.g. OpenAI, Microsoft, Google,..) which makes sense. I think the text has some great ideas in it.
Some parts of it are still unclear though. For example, what does it mean “to specify the parameters”, or “to give all relevant information”? In any case, it seems to me that for the model provider it’s going to be difficult to give hard guarantees on some aspects. I understand why Sam Altman of OpenAI “threatens” to leave the EU. It’s not intended as a threat. I’m sure he’s genuinely concerned with the question “We want to comply but is it feasible technically?”
Yesterday, EU lawmakers passed a draft of the EU AI Act which proposed transparency requirements for providers of foundation models like ChatGPT. Do they currently comply with the draft act? Researchers at @StanfordCRFM & HAI found that they often do not. pic.twitter.com/LrSy8TSOQd
— Stanford HAI (@StanfordHAI) June 15, 2023
All of these issues combined lead us to a rather distinctive approach to chatbots. Distinctive in the sense that I haven’t seen anyone writing about this approach yet. Given that the entire world seems to be rightfully adopting a “human in the loop”-stance about AI, not so distinctive at all.
Human editors for the win
The problem we had in previous years is that although it was possible for human content creators to create natural-feeling rule-based chatbot conversations using advanced tools and methods, it takes time to do so.
To understand why that is, one needs to know how typical rule-based chatbots are created. In a way one can think about this as creating a huge flowchart that contains all the possible paths of the conversation. However, to make this flowchart manageable we use a great deal of technology to generalise over sentences, reuse parts of the flowchart, parametrise sentences, keep a conversation history,… The underlying technology keeps most exponential complexity away. But still, the number of possible paths one needs to add is vast, making the entire process of creating these flowcharts time-intensive.
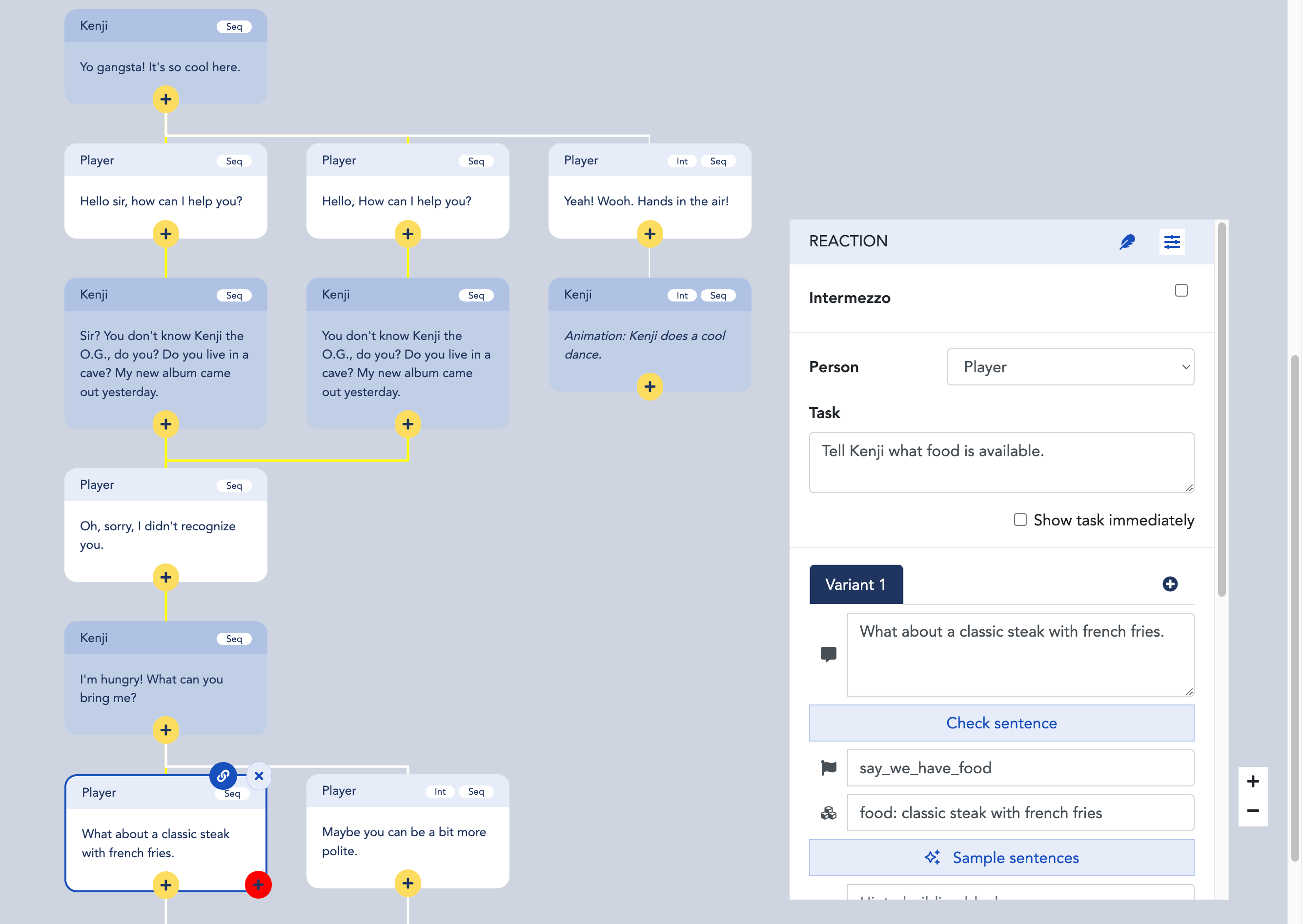
The above flowchart is an example of this, taken from our own content creation tool. At the point where the conversation is expecting the user to say he can offer a particular food, the system is smart enough to know (almost) all foods, and to know all variations of the sentence “I can bring you the food …” based on just a few examples. However, a human content creator still needs to provide these few examples for each expected “intent” / point in the conversation.
To create a great conversation can take weeks. The common public perception that chatbots were not working adequately before the recent generative AI breakthrough is fair, but only because it was too time-consuming for people to create this kind of conversation themselves.
What we are doing right now is creating these flowcharts using generative AI for human review. This is not simple prompt-based dialogue generation: this chatbot has many layers, components, features and other classifiers on top of it to generate everything our dialogue model expects.
Note: at the time of execution, we do make use of generative AI. We have a smaller Google Bert-based model that aligns the chatbot response perfectly to the previous utterance of the speaker, but it operates in an extreme sandbox making it completely safe to use. If the system is in doubt of a particular response, it will also ask a self-deployed LLM whether the player response was adequate or not (without any response generation), to determine the path to take. However, these smaller models are rather small subcomponents of our approach; they do not play a central role nor do they not introduce any of the risks highlighted earlier.
A conversation that may have taken up to 20 days in the past to create, can now be created in just a day.
One could argue that we may soon solve the capability problem ( = the challenge of making chatbot responses “desired, truthful and meaningful”) in its entirety. And one may argue that we may soon solve all the issues mentioned before. Why bother using generative AI to make the traditional chatbot approach with a human editor more efficient? A practical answer is that the Mount Doom example on the cover of this article is still very real today, even with GPT-4 (even when using a vector store with encoded world knowledge).
A more fundamental answer is that I believe having a human editor involved will still add value for a long time to come, whether it is to remove bias, enforce specific responses, deepen the conversation or to make it more funny or interesting. Even if starts to handle even more complex tasks well and the hallucinations stop entirely, I think the responses will be mediocre still. Believing we will make great strides in solving the capability problem doesn’t mean the human-centric approach stops making sense.
“It totally makes sense to extract controllable models from generative AI. In fact, we’re doing something similar in our own research projects, where we’re using it to generate test data and ontologies.”
Walter Daelemans, Professor of Computational Linguistics.
Although the human centered argument was the main driver for our approach, the approach solves all the risks of generative chatbots:
- No data privacy issues: there is no need to send any data to the outside.
- No performance issues: a response time of 40 milliseconds and an excellent SLA can easily be guaranteed as with any classic chatbot approach.
- Copyright issues are not solved automatically but at least a thorough and realistic check can be done.
- It extends the tasks that can be done: for example, if an extended set of vocabulary or grammar needs to be used, a content creator can easily adapt the flowchart until these requirements are met.
- It adds predictability: the resulting flowchart can be easily read and checked by humans. The flowchart can also be supplied as documentation to regulators.
- If a human upon review detects any inconsistencies or bias issues, they can be easily removed.
This way, we can unlock the game-changing potential of AI for chatbots while taking responsibility for mitigating risks effectively, involving human editors to create additional value where it makes sense.